Sarvam 105B: India's First Competitive Open-Source LLM
2026-03-07 · Gaurav Sharma · technology

Sarvam 105B: India's First Competitive Open-Source LLM Has Arrived
India just stopped watching from the sidelines. With the unveiling of Sarvam 105B at the India AI Impact Summit in February 2026, Bengaluru-based Sarvam AI just released another regional language model which planted a flag on the frontier AI map. This is India's open-source LLM moment, and it's bigger than most people are giving it credit for.
Let's be direct: for years, the narrative around Indian AI has been one of consumption, not creation. Indian engineers build the world's AI products, but the foundational models powering them have been American, Chinese, or European. Sarvam 105B — and its sibling, Sarvam 30B — represent a genuine, technically credible challenge to that status quo.
What Is Sarvam 105B, and Why Does It Matter?
Sarvam AI, founded by IIT alumni Vivek Raghavan and Pratyush Kumar, has been quietly building toward this moment. The company has raised over $41M from Lightspeed, Khosla Ventures, and Peak XV Partners — serious backers who don't write cheques for science projects. The result of that investment is now public: two open-source reasoning models trained entirely from scratch, on Indian soil, using compute provisioned under the IndiaAI Mission.
The headline numbers for Sarvam 105B:
- 105 billion parameters using a Mixture-of-Experts (MoE) architecture
- 128,000 token context window — enabling complex, multi-step agentic reasoning
- 22 official Indian languages supported natively
- Trained across pre-training, supervised fine-tuning (SFT), and reinforcement learning (RL) — the full stack, in-house
- Available on HuggingFace, AI Kosh, and via Sarvam's API
The smaller sibling, Sarvam 30B, is no slouch either — trained on nearly 16 trillion tokens with a 32,000 token context window, it matches or approaches the performance of models from Google, Mistral, Alibaba, and Nvidia on several reasoning and coding benchmarks.
The Architecture Bet: Why Mixture-of-Experts Is the Right Call
The MoE architecture has been vindicated repeatedly over the past two years, from Mistral's Mixtral to DeepSeek's R1. The core insight is elegant: you don't need to activate all parameters for every token. Route each token to the most relevant expert sub-networks, and you get the capacity of a massive dense model at a fraction of the inference cost.
For Sarvam, this wasn't just a performance optimisation, it was a strategic necessity. Building a 105B dense model and serving it economically across government, enterprise, and consumer use cases in India would be a deployment nightmare. MoE makes the model practical. The stated goal was to deliver strong reasoning, coding, and agentic capabilities while remaining practical to deploy and MoE is central to achieving that balance.
The 128k context window on the 105B model is equally significant. Long-context capability is what separates a chatbot from an agent. If you're building document-processing pipelines for Indian courts, multi-turn customer service for a bank, or code-generation tools for enterprise software teams, you need a model that can hold a lot in its head. Sarvam 105B can.
Sarvam 105B vs. DeepSeek R1: The Benchmark Story
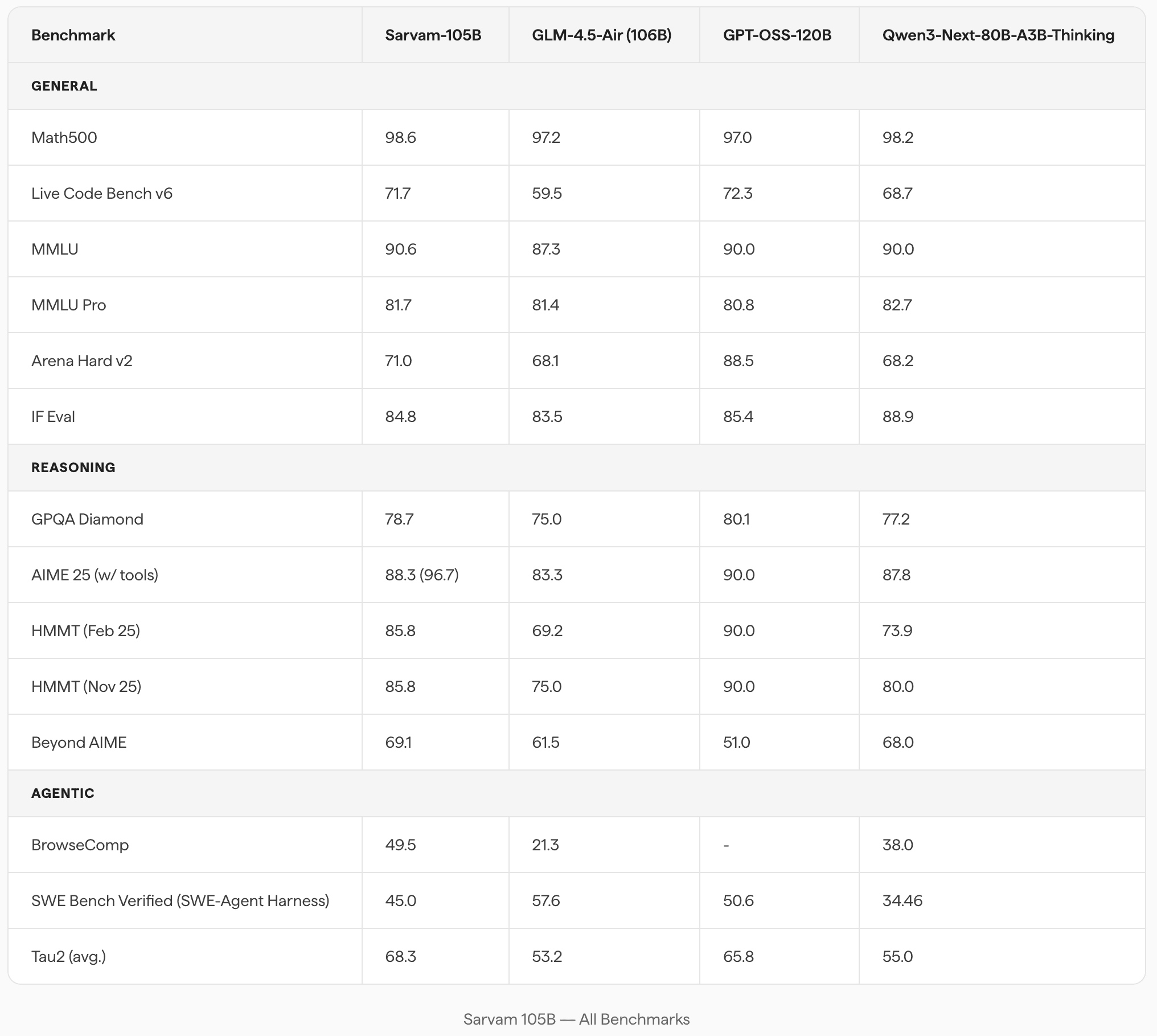
Here's where it gets genuinely exciting with some measured optimism alongside the enthusiasm.
Sarvam 105B reportedly outperforms DeepSeek R1 on several benchmarks despite being one-sixth the size (105B vs. DeepSeek R1's 600B+ total parameters). It also reportedly offers better cost efficiency than Google's Gemini Flash. These are not trivial claims.
Independent analyses confirm competitive performance particularly in language understanding, coding, and reasoning tasks against international peers. For an Indian model trained from scratch — not fine-tuned from an existing base, this is a remarkable result.
That said, Sarvam's own team is admirably honest about the ceiling. As co-founder Vivek Raghavan put it: Models like Gemini or ChatGPT are still an order of magnitude larger, so we are not claiming to be at par with them yet. That's the right framing. Sarvam 105B isn't GPT-5. But it doesn't need to be it needs to be the best open-source model for Indian use cases, and on that front, it appears to be winning.
One underappreciated point Raghavan raised: the tokenisation tax. Indian language scripts are systematically under-represented in Western model tokenisers, meaning they consume far more tokens per sentence than English inflating costs and degrading performance. Sarvam built its tokeniser from scratch with Indian languages in mind. As compute scales and tokenisation improves, the cost and quality gap will narrow faster than most analysts expect.
Sovereign AI India: More Than a Buzzword
Scepticism of AI sovereignty rhetoric is warranted when it's used to justify protectionism or mediocrity. But Sarvam's case is grounded in something real.
Consider the data dependency problem. Every Indian government agency, bank, or hospital that routes sensitive queries through a US-hosted model is, by definition, exporting data and ceding interpretive control. A model trained in India, on Indian compute, with Indian language data, and available via Indian infrastructure (AI Kosh is a government-backed platform) changes that calculus fundamentally.
Sarvam is building infrastructure for India's AI stack. The IndiaAI Mission compute that powered Sarvam 105B's training is the same infrastructure that future Indian AI startups will use. Every benchmark Sarvam clears raises the floor for what Indian AI can achieve.
The open-source economics argument is compelling too. By releasing both models openly on HuggingFace and AI Kosh, Sarvam is seeding an ecosystem. Researchers, startups, and government agencies can fine-tune, audit, and deploy these models without API lock-in or usage caps a fundamentally different value proposition from closed frontier models.
What Sarvam 105B Means for the Indian Developer Ecosystem
For Indian developers and engineering teams, the practical implications are significant:
- Enterprise and government deployments can now run a frontier-class Indic LLM on-premise or via sovereign cloud, without routing data offshore.
- Startups building for Bharat — vernacular voice assistants, regional e-commerce, agri-tech, health-tech — have a base model that actually understands the languages and contexts of their users.
- Researchers get a fully open model trained from scratch, with no murky data provenance or licensing restrictions that plague many open Western models.
- The cost story improves dramatically. MoE architecture plus better tokenisation means Indian-language inference is cheaper on Sarvam than on comparable Western models.
DeepSeek's open-source releases didn't just benefit Chinese developers, they forced the entire global AI industry to reckon with efficiency-first model design. Sarvam 105B has the potential to do something similar for the Indic AI space.
The Road Ahead: What to Watch
Sarvam has built something impressive, but the real test is what comes next:
- Third-party benchmark validation — independent evals on MMLU, HumanEval, and Indic-specific benchmarks will be critical for credibility.
- Ecosystem adoption — how quickly do Indian startups and government agencies actually deploy these models in production?
- The next training run — with IndiaAI Mission compute expanding, a 200B+ or multimodal Sarvam model feels like a matter of when, not if.
- Tokenisation improvements — Raghavan's point about the tokenisation tax is a genuine research frontier, and Sarvam is well-positioned to lead it.
India's AI story is no longer just about talent export. With Sarvam 105B, it's about building the foundational layer of a sovereign, open, and genuinely competitive AI ecosystem.
References
- Sarvam AI — Open-Sourcing Sarvam 30B and 105B
- TechBuzz — Sarvam AI Launches 105B Open-Source Models for India
- Inc42 — Sarvam And The Sovereign AI Dream
- BW Disrupt — Sarvam AI Unveils 105B-Parameter LLM
- Times of India — Sarvam's 105B model puts India on the frontier AI map